

Recently, I’ve been pondering the idea of building a metrics processing pipeline allowing data makers to quickly provision real-time transforms. Apache Flink would be the stream processing framework at the heart of this pipeline. Another service will need to be to orchestrate resource provisioning, distribution jobs on shared infra and effectively generate the flink DAG. When I say effectively, the component will essentially:
Selectively provision and import the required data streams (Kafka, Kinesis etc), by analysing the processing SQL
Provision the required Flink infrastructure (job/task managers) via Kubernetes. if required
Submit the job onto a node with the similar workload (preferably based on input sources)
Provide a control plane for re-processing
Provisioning streams for batch ingestion (if users want to use data from non-real-time sources)
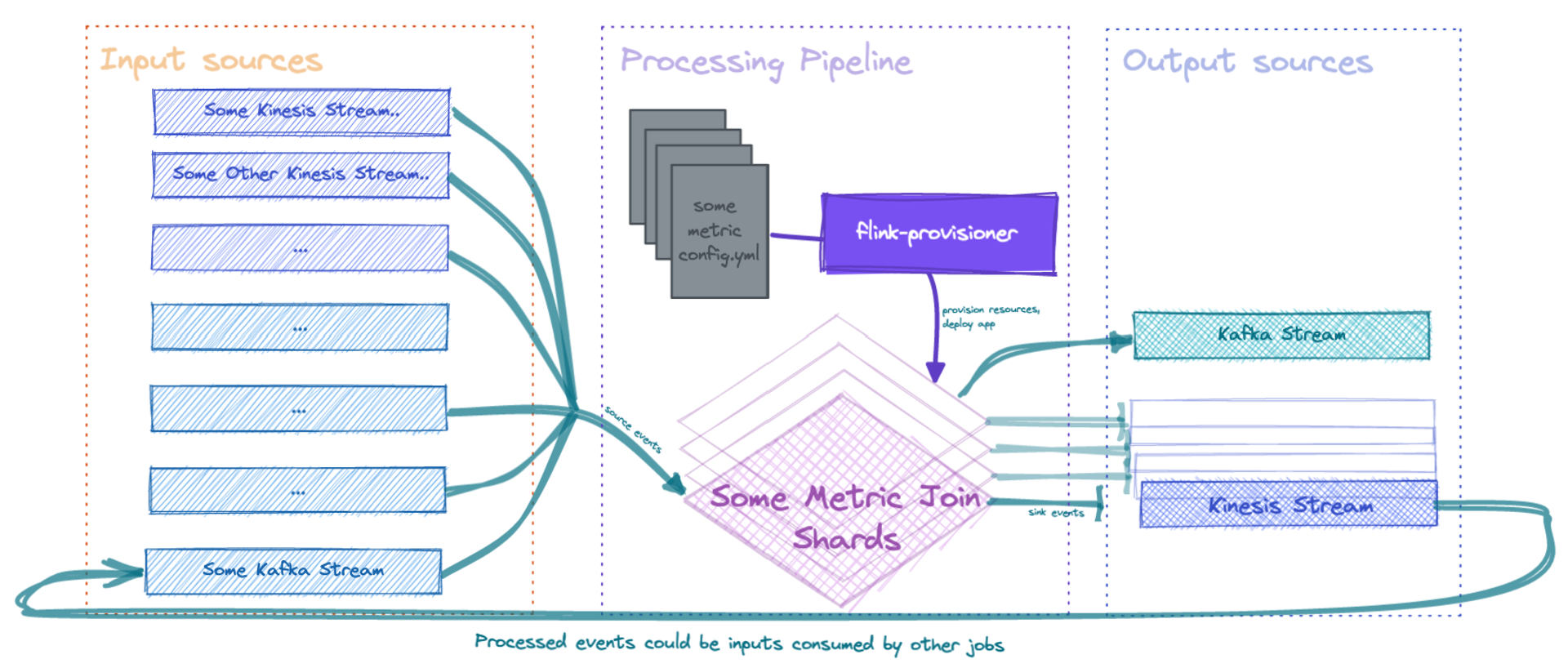
Proposed architecture diagram (with an example of how produced events could be consumed by other jobs for additional processing)
In theory, you would just write up a configuration file that contains the required data sources, processing SQL and the destination sink. The final platform will look like a codified alternative to Amplitude.